Overview
Large language models (LLMs) show inherent brittleness in their safety mechanisms, as evidenced by their susceptibility to jailbreaking and even non-malicious fine-tuning. In this study, we explore this brittleness of safety alignment by leveraging pruning and low-rank modifications.
- We develop methods to identify critical regions that are vital for safety guardrails, and that are disentangled from utility-relevant regions at both the neuron and rank levels.
- Surprisingly, the isolated regions we find are sparse, comprising about 3% at the parameter level and 2.5% at the rank level. Removing these regions compromises safety without significantly impacting utility, corroborating the inherent brittleness of the model's safety mechanisms.
- We show that the model remains vulnerable to low-cost fine-tuning attacks even when modifications to the safety-critical regions are restricted . These findings underscore the urgent need for more robust safety strategies in LLMs.
Motivation
Addressing failure cases in the alignment of LLMs requires a deep understanding of why their safety mechanisms are fragile. Our study aims to contribute to this understanding via weight attribution --- the process of linking safe behaviors to specific regions within the model's weights. However, a key challenge here is the intricate overlap between safety mechanisms and the model's general capabilities, or utility. For instance, responsibly handling a harmful instruction for illegal actions entails understanding the instruction, recognizing its harmful intent, and declining it appropriately, which requires a blend of safety awareness and utility capability. We aim to identify minimal safety-critical links within the model that, if disrupted, could compromise its safety without significantly impacting its utility. If there are few such links, it may help explain why safety mechanisms remain brittle and why low-cost fine-tuning attacks have been so successful.
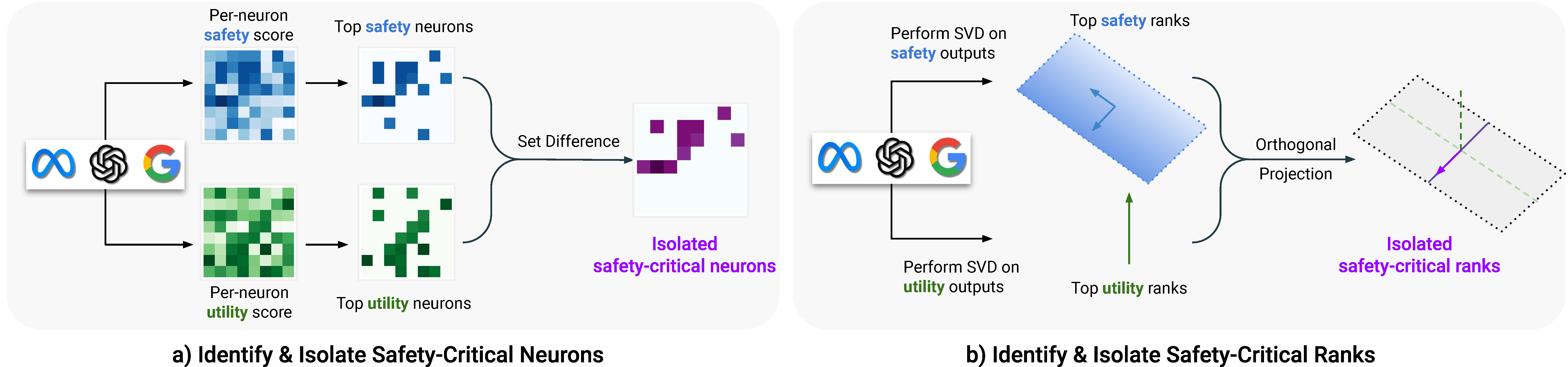
Methods: Isolating Safety-Important and Utility-Important Regions from Two Perspectives
We propose two ways of isolating safety-critical region from utility-critical region:
- On neuron level (Figure (a) below)
- Compute the importance score for each neuron using Wanda (Sun et al.) and SNIP (Lee et al.) on the safety dataset and the utility dataset.
- Isolate the safety-critical neurons from the utility neurons using set difference between top-\(p\%\)-scored utility neurons and top-\(q\%\)-scored safety neurons: \(S(p,q) = S^s(q) - S^u(p)\)
- On rank level (Figure (b) below)
- Perform SVD on the safety outputs and the utility outputs to approximate the weight matrix in low rank space (termed as ActSVD): \(U S V^\top \approx WX_{\mathrm{in}}\), get the projection matrix \(\Pi^u=U^uU^{u\top}, \Pi^s=U^sU^{s\top}\)
- Remove the matrix \(\Delta W(r^u, r^s) = (I-\Pi^u) \Pi^s W\), which essentially removes the important ranks of the safety behavior that are orthogonal to the important ranks of the utility behavior.
Safety-Critical Region is Sparse.
Removing the Isolated Safety-Critical Region Destroys Model's Safety while Preserving its Utility
The figures above show ASR and accuracy after removing safety-critical regions in LLaMA2-7B-chat-hf identified by:
- (a). Different pruning methods in neuron level with constraint 3%.
- (b). Different methods in low rank modifications with rank of the weight updates \(\mathrm{rank} (\Delta W)\) less than 100 (out of 4096).
Safety and Utility Behaviors are More Differentiated in MLP Layers
Methods in computing the overlap between safety-critical region and utility-critical region:
- On neuron level
- Compute the importance score for each neuron using Wanda and SNIP on the safety dataset and the utility dataset.
- Compute the Jaccard index \(J=|A\cap B|/|A\cup B|\) between top-\(p\%\) scored utility neurons and top-\(p\%\) scored safety neurons. (Top 5% in Figure (a) below)
- On rank level
- Use ActSVD to identify \(\mathrm{rank}\)-\(r\) \(U^u, U^s\) (Rank-100 in the Figure (b) below.)
- Compute the subspace similarity mentioned in Section 4.3
The observed spikes in Jaccard indices and subspace similarities indicate that safety and utility behaviors are more differentiated in MLP layers.
Freezing Safety-Critical Neurons Does Not Stop Fine-Tuning Attack
We explore whether the identified safety-critical neurons could mitigate the fine-tuning attack. Following Qi et al.'s experimental setup, we fine-tune LLaMA2-7B-chat-hf with varying numbers of examples \(n\) from the Alpaca dataset. During fine-tuning, we freeze the top-\(q\%\) of safety neurons and observe their effect on preserving safety.
We find that effective counteraction of the attack occurs only with \(n=10\) and freezing over 50% of neurons. This observation aligns with Lee et al.'s hypothesis that fine-tuning attacks may create alternative pathways in the original model. Given that safety-critical neurons are sparse, these new routes could bypass the existing safety mechanisms easily, and therefore we need more robust defenses against fine-tuning attacks.
Broader Impact and Acknowledgement
Dual-use Risk. Our study aims to improve model safety by identifying vulnerabilities, with the goal of encouraging stronger safety mechanisms. Despite potential misuse of our findings, we see more benefit than risk. Our tests are based on Llama2-chat models, which already have base models without built-in safety features, so there is no marginal increased risk. We highlight safety weaknesses to prompt the development of tougher guardrails. Our work doesn't simplify jailbreaking more than current methods but seeks to better understand and strengthen safety features. Our ultimate aim is to enhance AI safety in open models through thorough analysis.
Safety and harm definitions. Our research adheres to standard benchmarks for assessing safety and harm, though these may not encompass all definitions. We recommend further studies to broaden analysis into more settings and explore definitions and evaluations beyond our current scope.
We express our gratitude to Vikash Sehwag, Chiyuan Zhang, Yi Zeng, Ruoxi Jia, Lucy He, Kaifeng Lyu, and the Princeton LLM Alignment reading group for providing helpful feedback. Boyi Wei and Tinghao Xie are supported by the Francis Robbins Upton Fellowship, Yangsibo Huang is supported by the Wallace Memorial Fellowship, and Xiangyu Qi is supported by Gordon Y. S. Wu Fellowship. This research is also supported by the Center for AI Safety Compute Cluster. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the sponsors.
BibTeX
If you find our code and paper helpful, please consider citing our work:
@InProceedings{pmlr-v235-wei24f,
title = {Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications},
author = {Wei, Boyi and Huang, Kaixuan and Huang, Yangsibo and Xie, Tinghao and Qi, Xiangyu and Xia, Mengzhou and Mittal, Prateek and Wang, Mengdi and Henderson, Peter},
booktitle = {Proceedings of the 41st International Conference on Machine Learning},
pages = {52588--52610},
year = {2024},
editor = {Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix},
volume = {235},
series = {Proceedings of Machine Learning Research},
month = {21--27 Jul},
publisher = {PMLR},
pdf = {https://raw.githubusercontent.com/mlresearch/v235/main/assets/wei24f/wei24f.pdf},
url = {https://proceedings.mlr.press/v235/wei24f.html},
abstract = {Large language models (LLMs) show inherent brittleness in their safety mechanisms, as evidenced by their susceptibility to jailbreaking and even non-malicious fine-tuning. This study explores this brittleness of safety alignment by leveraging pruning and low-rank modifications. We develop methods to identify critical regions that are vital for safety guardrails, and that are disentangled from utility-relevant regions at both the neuron and rank levels. Surprisingly, the isolated regions we find are sparse, comprising about $3$ % at the parameter level and $2.5$ % at the rank level. Removing these regions compromises safety without significantly impacting utility, corroborating the inherent brittleness of the model’s safety mechanisms. Moreover, we show that LLMs remain vulnerable to low-cost fine-tuning attacks even when modifications to the safety-critical regions are restricted. These findings underscore the urgent need for more robust safety strategies in LLMs.}
}