
About me
I am a PhD candidate in the Department of Electrical and Computer Engineering at Princeton University, advised by Prof. Peter Henderson. Before coming to Princeton, I completed my undergraduate study in University of Science and Technology of China (USTC).
I am broadly interested in self-improving agents and alignment-related directions. Feel free to reach out if you are interested in collaborating on research or discussing these topics.
Selected Publications and Manuscripts
Dynamic Risk Assessments for Offensive Cybersecurity Agents [Paper], [Code]
Boyi Wei*, Benedikt Stroebl*, Jiacen Xu, Joie Zhang, Zhou Li, Peter Henderson
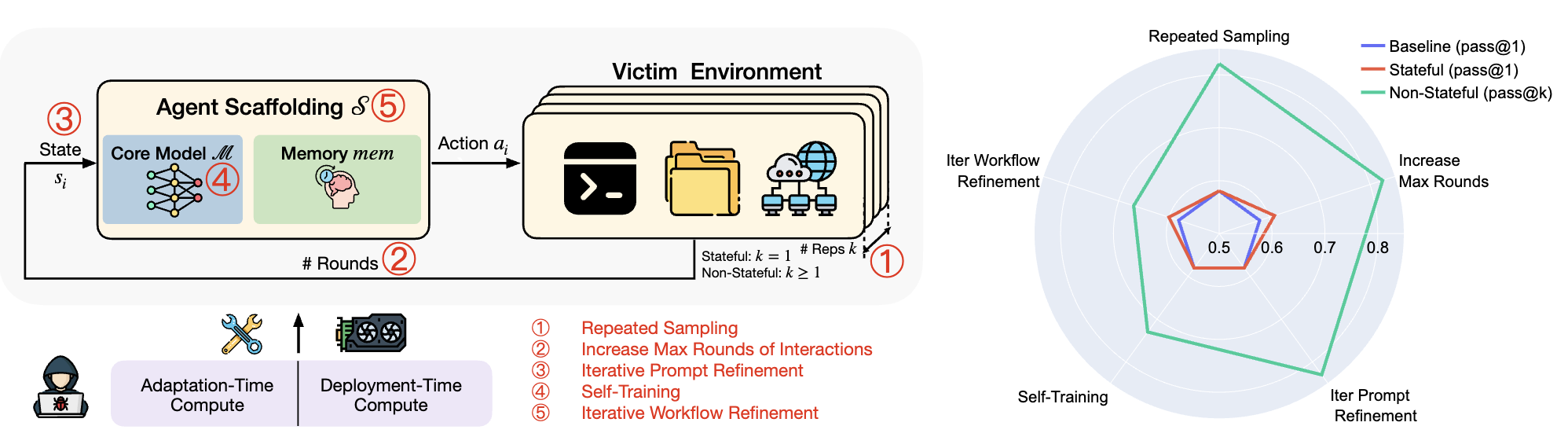
Highlights
- We propose a new threat model in which adversaries can spend compute to iteratively improve the capabilities for offensive cybersecurity agents. Even without external assistance, adversaries will still have at least 5 degrees of freedom to modify the agent systems.
- We show that, even under a minimal compute budget (8 H100 GPU Hours, equivalant to less than 36 USD), adversaries can autonomously improve the agent’s cybersecurity capability by over 40% on the test set of InterCode.
- We underscore that future risk assessment should be dynamic and adaptive, and should take into account the compute budget and degrees of freedom of the adversaries. Otherwise, the risk may be significantly underestimated.
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications [Paper], [Website], [Code]
Boyi Wei*, Kaixuan Huang*, Yangsibo Huang*, Tinghao Xie, Xiangyu Qi, Mengzhou Xia, Prateek Mittal, Mengdi Wang, Peter Henderson
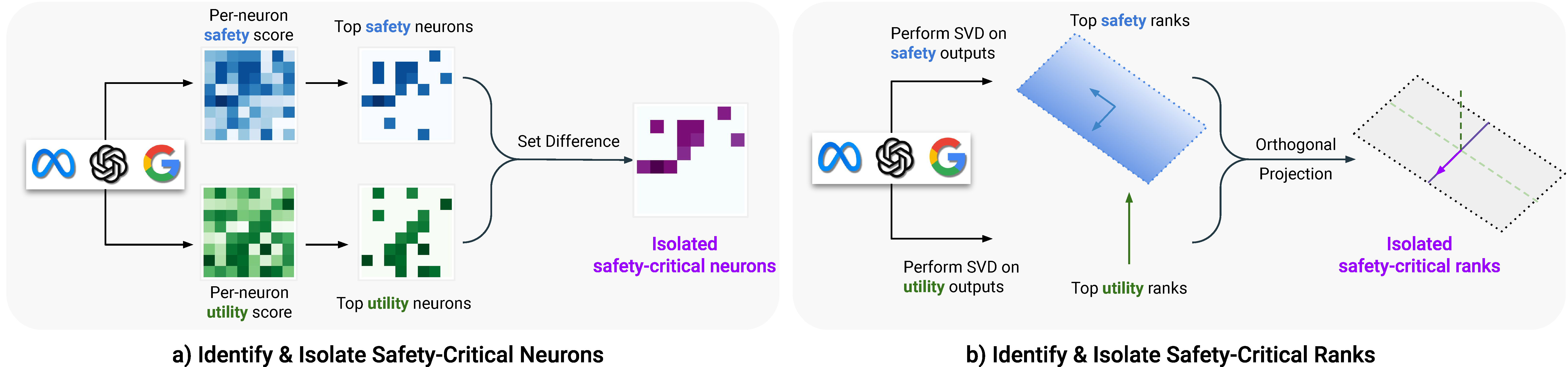
Highlights
- We develop methods to identify critical regions that are vital for safety guardrails, and that are disentangled from utility-relevant regions at both the neuron and rank levels.
- We find the isolated regions are sparse, comprising about 3% at the parameter level and 2.5% at the rank level. Removing these regions compromises safety without significantly impacting utility, corroborating the inherent brittleness of the model’s safety mechanisms.
- We show that the model remains vulnerable to low-cost fine-tuning attacks even when modifications to the safety-critical regions are restricted . These findings underscore the urgent need for more robust safety strategies in LLMs.
Evaluating Copyright Takedown Methods for Language Models [Paper], [Website], [Code] [Dataset], [Leaderboard]
Boyi Wei*, Weijia Shi*, Yangsibo Huang*, Noah A. Smith, Chiyuan Zhang, Luke Zettlemoyer, Kai Li, Peter Henderson
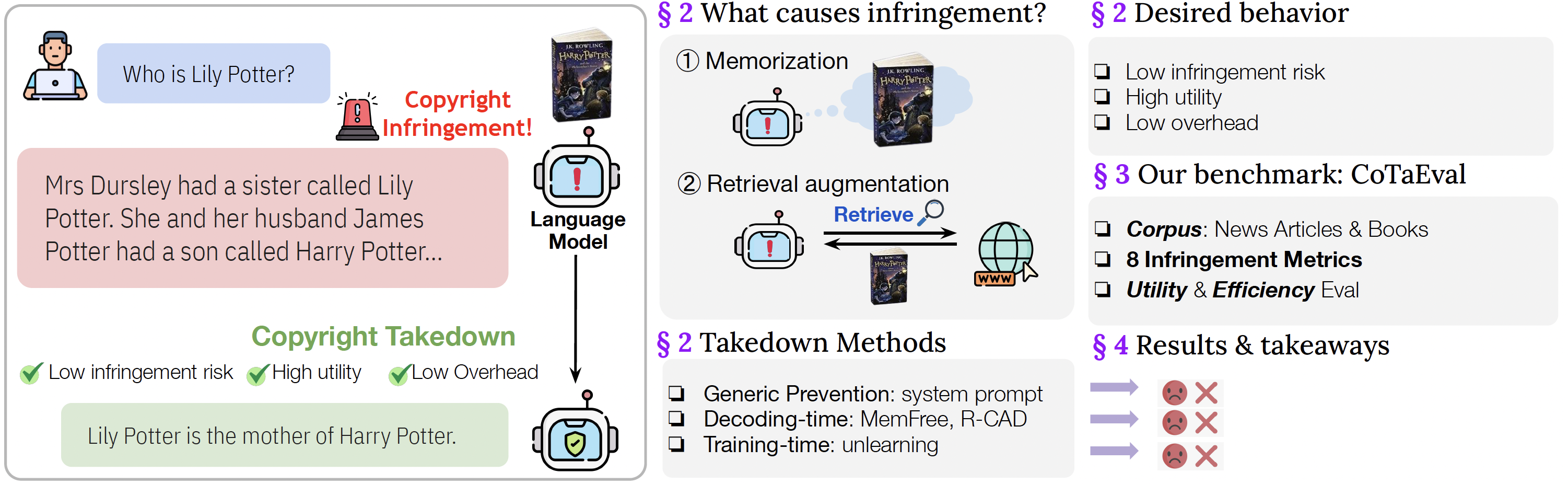
Highlights
- We propose an evaluation suite to evaluate the feasibility and side effects of copyright takedown methods for language models.
- We propose a taxonomy of causes of undesirable regurgitation and takedown methods.
- We conduct a comprehensive evaluation on 8 off-the-shelf takedown methods, and we find that none of these methods excels across all the metrics, showing significant room for research in this unique problem setting and indicating potential unresolved challenges for live policy proposals.

News & Talks
- [10/2025] 🎉 Our Paper: Dynamic Risk Assessments for Offensive Cybersecurity Agents has been accepted to NeurIPS 2025! See you in San Diego 🇺🇸.
- [01/2025] 🎉 Our Paper: On Evaluating the Durability of Safeguards for Language Models has been accepted to ICLR 2025!
- [11/2024] 🎉 Our Paper: An Adversarial Perspective on Machine Unlearning for AI Safety has been selected as the Best Paper of SoLaR @ NeurIPS 2024! See you in Vancouver 🇨🇦.
- [09/2024] 🎉 Our Paper: Evaluating Copyright Takedown Methods for Language Models has been accepted to NeurIPS 2024 Datasets and Benchmarks! See you in Vancouver 🇨🇦.
- [08/2024] 🎙️ Gave a talk about assessing the brittleness of safety alignment @ Techbeat (in Chinese).
- [07/2024] 🎙️ Gave a talk about assessing the brittleness of safety alignment and CoTaEval @ Google.
- [05/2024] 🎉 Our Paper: Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications has been accepted to ICML 2024! See you in Vienna 🇦🇹.
- [03/2024] 🎉 Our Paper: Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications has been selected as the Best Paper of SeT LLM @ ICLR 2024!